

Google’s Gary Illyes answered a question about canonicalization, indexing, and core algorithm updates that provide a clearer picture of how different systems work together but independently.
A search marketer named David Minchala asked if Google’s canonicalization processes were still working, but in a slower way during a core algorithm update. The answer to this question is interesting because it provides a way to better understand how these backend processes work.
David’s question used the word “pose,” which means to present an idea or statement for consideration as a possible fact.
This is the question:
“Position: During major algorithm updates (and maybe any major updates?), indexing services like canonicalization (i.e. selecting the URL to index and combining all signals from other known duplicate URLs) still they work, but they are slower. maybe much slower.
Any chance for a comment, Gary Illyes or John Mueller? It might also be a good topic for Search Off the Record: What are the technical demands on Google to implement core updates and how might this affect ‘normal’ services like crawling and indexing.”
Google’s Gary Illyes responded by saying that the proposed claim is incorrect, using an analogy to explain how the two work. Gary specifically mentions the index selection process (where Google chooses what goes into the index) and canonicalization (choosing which URL represents the web page when there are duplicates).
Explained:
“Position is wrong. these systems are independent of “core updates”.
Think of basic upgrades like playing with cooking ingredients: change the amount of salt or message you put in your stir-fry, and you can radically change the outcome.
in this context index selection and canonization is more about what happens in the salt pans or msg factories; there’s still not much to do with the kitchen.”
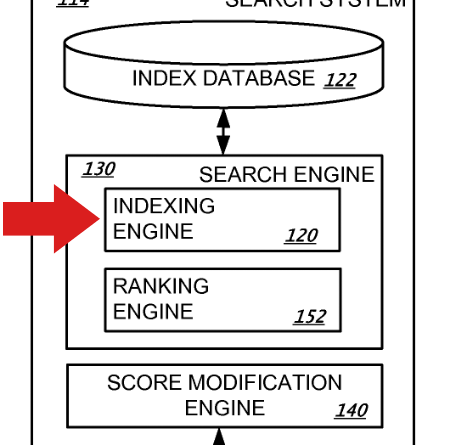
Google indexing engine
In other words, what happens in a core update happens independently of the index selection and canonicalization processes. This way of looking at it, as Gary Illyes suggested, aligns with many of Google’s patents that describe how search systems work. When referring to a search engine, the patents describe it as a collection of engines, using the phrase “indexing engine” when referring to indexing.
For example, in a patent illustration there is an indexing engine, a classification engine, and a score modification engine. Data flows in and out of each engine where it is processed according to its function.
Screenshot of a Google patent
Flow diagram representing a search system. It includes a query input, search results, components such as an index database, an indexing engine, a ranking engine, and a score modification database.
The screenshot above makes it easier to understand what a search engine is and how the different parts work together and separately.
Read the LinkedIn discussion here.
Featured image by Shutterstock/Roman Samborskyi
[ad_2]
Source link



