

It only took twenty-four hours after Google’s Gemini went public for someone to notice that the chats were showing up publicly in Google search results. Google was quick to respond to what appeared to be a leak. The reason why this happened is quite surprising and not as sinister as it seems.
@shemiadhikarath he tweeted:
“Hours after @Google Gemini launch, search engines like Bing have indexed public Gemini conversations.”
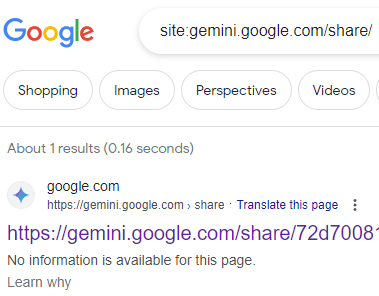
They posted a screenshot of the search at gemini.google.com/share/
But if you look at the screenshot, you’ll see that there’s a message that says, “We’d like to show you a description here, but the site won’t allow us.”
In the early morning hours of Tuesday, February 13, Google Gemini chats began to appear in Google search results, with Google showing only three search results. By afternoon, the number of leaked Gemini chats showing up in search results had been reduced to a single search result.
How were the Gemini chat pages created?
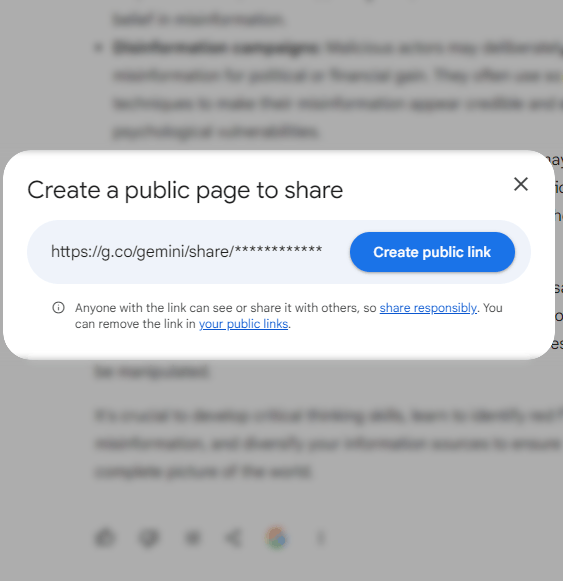
Gemini provides a way to create a link to a publicly viewable version of a private chat.
Google does not automatically create web pages from private chats. Chat pages are created by users using a link at the bottom of each chat.
Screenshot of how to create a shared chat page
Why were the Gemini chat pages indexed?
The obvious reason the chat pages were crawled and indexed is because Google forgot to put a robots.txt in the root of the Gemini subdomain (gemini.google.com).
A robots.txt file is a document for controlling crawler activity on websites. A publisher can block specific crawlers using standardized commands in the Robots.txt protocol.
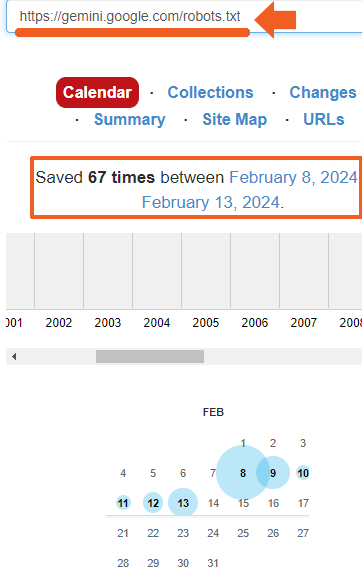
I checked the robots.txt file at 4:19 am on February 13th and saw that there was one:

I then checked the Internet Archive to see how long the robots.txt file has been around and discovered that it’s been there since at least February 8th, the day the Gemini apps were announced.
Screenshot from Internet Archive
This means that the obvious reason the chat pages were crawled isn’t the correct reason, it’s just the most obvious reason.
Even though the Google Gemini subdomain had a robots.txt that blocked both Bing and Google web crawlers, how did they end up crawling and indexing these pages?
Two-way private chat pages discovered and indexed
There might be a public link somewhere. It is less likely, but perhaps possible, that they were discovered through browsing history linked from cookies.
It is more likely that there is a public link.
I asked Bill Hartzer (@bhartzer) about it and discovered a public link for one of the indexed pages:
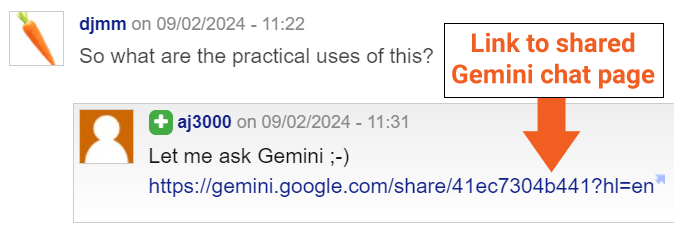
So now we know that a public link is very likely to get these Gemini Chat pages crawled and indexed.
Bill Hartzer offered this observation:
“Although the Gemini URL is being blocked in the robots.txt file, there is a link to the Gemini URL in a blog comment, so the Gemini URL is indexed.
This just shows that Google will still index URLs that cannot be crawled in the robots.txt file.
If Google really wanted to make sure the Gemini URL wasn’t indexed, it COULD crawl the robots.txt file and add a noindex meta tag to the pages. Maybe Google should take its own advice here?”
Why did chat pages start dropping out of search results?
But if there is a public link, why did Google start dropping chat pages? Has Google created an internal rule for the search crawler to exclude web pages in the /share/ folder from the search index, even if they are publicly linked?
Information about how Bing and Google search index content
Now here’s the really cool part for all you search geeks interested in how Google and Bing index content.
Microsoft’s Bing search index responded to Gemini content differently than Google search did. While Google was still showing three search results in the early morning hours of February 13, Bing was only showing one result for the subdomain. There was a seemingly random quality to what was indexed and how much.
Why were the Gemini chat pages leaked?
Here are the known facts:
Google had a robots.txt in place since February 8th. Both Google and Bing indexed pages from the gemini.google.com subdomain. Both Google and Bing may have discovered links to the chats and subsequently indexed them. Search engines indexed the content regardless of the robots.txt and then started dumping them.
This brings us back to the question of why these pages started dropping out of both Google and Bing search results. I guess the Google Gemini chat pages are low quality web pages that are not worth showing for essentially long searches (site:gemini.google.com/share/). There’s really no useful reason to show these pages in search results.
Content blocked by Robots.txt can still be discovered, crawled and ended up in the search index and if the pages are useful they can also be ranked, unless they are not useful. I think this may be the case.
[ad_2]
Source link



